《面试实录》 阿里一面,深剖Map底层结构与原理
- 对线面试官
- 面试实录
- Java
本期是【面试实录】系列文章的第 4 期,持续更新中.....。
- 欢迎关注+订阅,持续更新中!!!致力打造校招核心面试攻略~
- 根据秋招春招上岸大厂面试经历以及身边朋友上岸面试录音模拟面试现场,并整合面试常考知识点,通俗有趣的去讲解 "八股文",不一样的系列,轻松掌握知识~
【面试实录】专栏系列目前已经连载 4 篇了,据说看了这个系列的朋友都拿到了大厂offer~
考点速查
本期会模拟面试 Map 相关内容。
涉及知识点,Map 常使用实现类使用场景,特性;Hash算法;HashMap原理剖析;分段锁;ConcurrentHashMap;
本期题改编自 ——2022届春招 阿里供应链 一面
面试现场
1111
叮叮叮......
面试官:“你好,我是XX面试官,请问是小龙吗?”
小龙:“您好,面试官,我是小龙”
面试官:“好的,现在有空吗,我们开始面试吧”
小龙:“嗯嗯,准备好啦”
.......
other questions
.......
面试官:“我看你简历上有提到你已经是 ‘老Map’ 了对吧。”
小龙:“是的”
面试官:“好的,那 Map 接口下,你常用的实现类有哪些?能简单聊聊吗?”
独白:“又得扯HashMap ConCurrentHashMap 了....。”
小龙:“我经常使用HashMap、 LinkedHashMap、TreeMap这些。”
面试官:“那它们分别在什么场景下使用呢?”
小龙:“一般情况涉及到键值对的存取,我们都会第一时间考虑使用 HashMap。不过,在某些特定场景,比如:我们需要根据 key 顺序去存储键值对,TreeMap 可能就更合适啦。“
小龙:”因为 TreeMap 底层是基于红黑树实现的,可以提供顺序访问,不过 TreeMap 键值都不能为 null,而且时间复杂度是 O(logn)。因此,在实际应用场景中,应当综合考虑二者的特性去择优处理。“
小龙:”而对于 LinkedHashMap,它的实现是通过为条目(键 值对)维护一个双向链表。平时主要用来处理一些特定的应用场景。”
小龙:”比如:去构建一个对空间占用很看重的一个资源池,可以自动将不常用的资源释放掉,例如去模拟 LRU 缓存淘汰策略,就可以使用 LinkedHashMap 去模拟。“
面试官:“好的,我们接着往下聊哈。那你有了解过 HashMap 的底层实现原理吗?平时有没有仔细研究过它的源码呢?”
小龙:“这个有仔细研读过,收获颇多。”
面试官:“那首先你能给我讲讲你对 Hash 算法的理解吗?”
小龙:“简单来说,其实它就是一种将任意长度的输入转为为固定长度的输出的映射规则。”
面试官:“那这个映射会不会有什么问题呢?”
小龙:“当然,由于任意长度—>固定长度,随着 hash 次数增加,后面必定出现 哈希冲突。”
面试官:“那这个冲突能避免吗?”
小龙:“hash冲突不可避免 只能说减少冲突。”
面试官:“那你有了解过哪些方法可以去解决这个 Hash 冲突呢?”
小龙:“嗯,比如:拉链法、开放地址、多哈希算法,当然在分布式某些场景中,我们还可以使用一致性Hash算法。”
面试官:“好的,那接下来你说说 HashMap 的底层数据结构吧!”
小龙:“JDK1.7 及以前是数组+链表,JDK1.8 是数组+链表+红黑树。”
面试官:“默认负载因子是多少呢,并且这个负载因子有什么作用?”
小龙:“负载因子默认0.75,它是在计算扩容阈值时用的。”
面试官:“创建 HashMap 时,不指定散列表数组长度,初始长度是多少呢?”
独白:“wc,问这么简单吗?”
小龙:“默认初始长度16啊。”
面试官:“那散列表是new HashMap()时创建的么?”
独白:“这个到是稍微有点意思~”
小龙:“不是在new HashMap()创建的,它使用懒加载,是当第一次调用 put() 方法时 执行putVal() 时才创建散列表。”
面试官:“那说说 HashMap put() 写数据的具体流程吧,尽可能的详细点!”
独白:“好吧,本来想以普通人身份相处,换来的却是疏远,不装了,摊牌了。是你叫我详细一点的,我可以直接把源码一条龙给你背下来.....。”
小龙:“ 1、首先map.put(“公众号” , “小龙coding”); ”
小龙:“2、调用 key 对象的 hashcode() 方法计算 key-"公众号" 的hash 。”
小龙:“3、然后经过扰动函数使其 hash 值更散列(调用 key 对象的 hashcode() 方法计算出来 hash 值,将 hash 值的高 16 位右移并与原 hash 值取异或运算(^),混合高 16 位和低 16 位的值,得到一个更加散列的低 16 位的 hash 值)”
小龙:“4、接下来进入putVal() 方法,判断散列表是否为空 也就是 put() 方法第一次调用才初始化 HashMap 的存储结构 Node<k,v>[] table 散列表 初始为数组长度16”
小龙:“5、调用 (n - 1) & hash 【细节解释:(散列表数组长度-1) 与 (hash值得到将要把元素插到哪里的数组下标)】”
小龙:“6、判断数组该位置是否为空”
小龙:“如果为空 新创建一个结点直接插入 tab[i] = newNode(hash, key, value, null);如果插入位置已经有值了tab[i]!=null,并且桶位中的该元素,与你当前插入的元素的 key 完全一致,表示后续需要进行替换操作,否则就需要往该结点后添加元素。”
独白:“估计面试官与正在看的你已经蒙了,这是为了全面细致的拉通分析一遍,面试可以简单的说。”
小龙:“插入前需要判断是否为树结构,若为树结构按照树结构的插入结点方法插入,不是树结构则按照链式结构插入结点方法插入。”
小龙:“若为链表结构,遍历改链表,判断是否有与你要插入的 key 一致的 node。”
小龙:“如果没有则将结点插入到该链表末尾(1.8尾插法 1.7头插法),并判断插入后是否达到树化条件(链表长度>=8 进入treeifyBin(tab, hash);进入该方法还需要判断当前数组长度>=64才能树化,如果<64则扩容)”
小龙:“到相同元素则需要替换。”
小龙:“7、完成插入操作了 ++modCount(散列表结构结构被修改的次数–替换 Node 元素的 value 不算)”
小龙:“8、最好 size 自增,如果自增后的值大于扩容阈值,则触发扩容 resize();”
独白:“没有源码,这里可能基础差的看起来很吃力,需要看全代码跟踪解析,有每一步调试+注释,一步一步跟着方法进,注释写的很清楚,需要可以公众号【小龙coding】后台回复【HashMap】”
面试官:“叫你说详细一点,用不着这么详细,哈哈。”
面试官:“我们加快脚步了,Node对象内部的 hash 字段,这个 hash 值是 key 对象的 hashcode() 返回值么?”
小龙:“Node 对象里面的 hash 值并不是直接 key.hashcode() 得到, 还要经过 扰动函数。“
面试官:”这个 hash 值是怎么得到呢?“
小龙:”将 hash 值的高 16 位右移并与原 Hash 值取异或运算(^),混合高 16 位和低 16 位的值,得到一个更加散列的低 16 位的 Hash 值。“
面试官:”JDK8 HashMap 为什么引入红黑树?解决什么问题?“
小龙:”引入红黑树我认为是这样 当产生 hash 冲突时会形成链表 当数据多了冲突多了 链表越来越长 造成链化 此时查询将特别耗时 本来时间复杂度为O(1) 结构可能达到 O(n),引入红黑树可以优化查询。“
面试官:”HashMap 什么情况下会触发扩容呢?“
小龙:”当它未初始化,第一次 put 时会触发扩容。后面插入值,当大于扩容阈值时也会触发扩容。“
面试官:“HashMap 如何确定元素放在哪个位置呢?”
小龙:“首先经过扰动函数计算得到hash值;然后通过 (n - 1) & hash 判断当前元素存放的位置。”
面试官:”HashMap 有什么问题吗?在实际应用场景中。“
小龙:”因为 HashMap 非线程安全,可能出现并发线程安全问题。在JDK1.7中,当并发执行扩容操作会造成环形链,然后调用 get 方法会死循环。JDK1.8中,并发执行put操作时会发生数据覆盖的操作。“
面试官:”那有什么解决办法吗?“
小龙:”可以使用 Hashtable,因为它的方法加了 synchronized,可以做到线程安全。“
小龙:”不过,由于它锁的是整个表,导致效率低下。因此,我们一般使用的是 ConcurrentHashMap“
面试官:“好的,那你能简单介绍一下 ConcurrentHashMap 吗?为何它的性能效率更高呢?”
小龙:”ConcurrentHashMap JDK1.7 引入了分段锁,数据结构采用Segment数组+HashEntry数组+链表。Segment 继承了 ReentrantLock,一个 Segment[i] 就是一把分段锁。比起 Hashtable 锁粒度更细,性能更高。”
一个Segment中包含一个HashEntry数组,每个HashEntry又是一个链表结构
static final class Segment<K,V> extens ReentrantLock implements Serializable{
transient volatile HashEntry<K,V>[] tables;
//.....
}
static final class HashEntry<K,V>
{
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
面试官:“何为分段锁?”
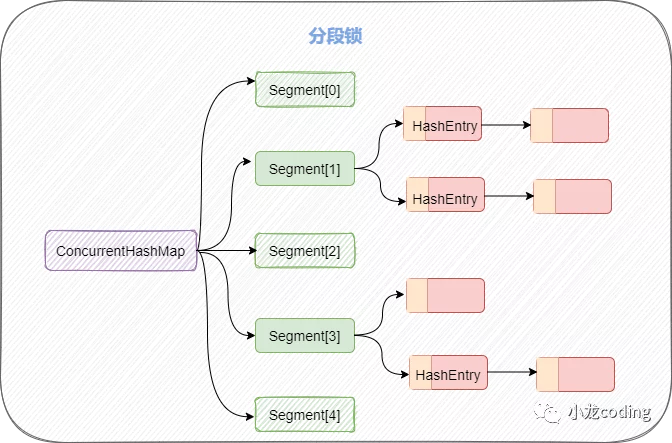
小龙:“一个 Segment 就相当于一把锁,它只锁住这个槽位,其他的并不受影响。ConcurrentHashMap 将 hash 表分为 16 个桶(默认值),诸如get,put,remove 等常用操作只锁当前需要用到的桶。”
小龙:“试想,原来 只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。”
面试官:“不过我们现在都基本用 JDK1.8 啦,JDK1.8 它也是使用分段锁吗?”
小龙:“JDK1.8 后,它做出了很大改变,数据结构采用Node数组+链表+红黑树,抛弃Segment分段锁,采用CAS+synchronized,锁粒度更细,只锁住链表头节点(红黑树根结点),不影响其他哈希桶数组元素的读写,提高并发度。”
面试官:“好的,挺不错的。最后一个问题,你知道 ConcurrentHashMap 为什么不支持 null value吗?”
小龙:“这个很简单啊,vaule 为 null,有两种情况,可能是存的值为 null 或则是没有映射到值 返回null;”
小龙:”HashMap 用于单线程下可以通过 ContainsKey() 区分这两种情况;“
小龙:“但是 ConcurrentHashMap用于多线程场景,本来是没有映射 ContainsKey() 返回fasle,但是可能在你调用 ContainsKey() 检查时新线程插入null值,返回ture,存在二义性”
面试官:“牛逼,基础很好!继续加油。”
独白:“不愧是我,真男人是也!”
知识总结
本期我们通过面试模拟简单介绍了Map相关面试中重点考察的内容,重点剖析了 HashMap 与 ConcurrentHashMap 相关集合。
面试重点
Map 常使用实现类使用场景,特性;Hash算法理解;HashMap原理剖析;分段锁理解;ConcurrentHashMap原理,底层数据机构,JDK1.8 与JDK1.7 区别。